 @ 2012-04-04 6:11 AM (#7092 - in reply to #7007) (#7092) Top
@ 2012-04-04 6:11 AM (#7092 - in reply to #7007) (#7092) Top
Country : United States
MellowMelon posted @ 2012-04-04 6:11 AM
Here's an attempt at reanalyzing the TVC scores using a system similar to the CTC. For each test, the top 10% and median 10% scores are computed, just like in the CTC formulas. I'm not sure of a good analogue for the computation of PuPo, and I'm not sure if it's appropriate in this case, so I weighted each test by the same amount. Then the normalized score is equal to 100 * 2^((score - top10%score)/(top10%score - median10%score)). Using this for the normalized scores and the usual "best 3 out of 4" metric, this was the new top 20:
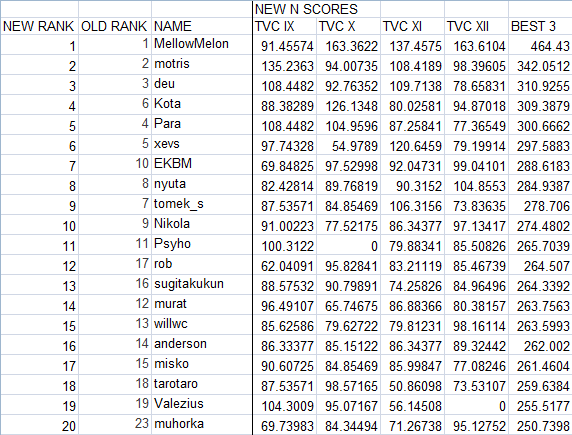
Full XLS spreadsheet: http://mellowmelon.files.wordpress.com/2012/04/lmi-tvc-alt-rankings...
Not too many rank changes here, and the top 3 stayed the same. My main reasoning for considering this was that the system used here seemed a bit sensitive to the top score. People who had their bad day on TVC X or TVC XII seemed to get a lucky break, while people with their best relative performance on those tests didn't have it count as much - reminiscent of motris's complaint about his Samurai solve in the Marathon being his best relative performance yet still getting thrown out as his worst time. Whether the end rankings with this formula make more sense than the old I'm not entirely sure of, but perhaps other people can offer their own views.
Actually, this whole issue of things being sensitive to the top score is something I've felt is a bit of a weakness of the current LMI ratings in general. The stated reason is to give the top scorer appropriate compensation for their performance, but it seems weird to implement this by knocking everyone else's prorated score down. The exponential distribution the CTC introduced, based around the top 10% score instead of the top score only, seems to solve this problem and possibly do a better job of compensating the top scorer, since there is a steep rate of change in the exponential distribution near the top. I admit I haven't thought about all of the relevant issues in their entirety though. Also, if you check the full XLS file you'll realize the formula probably needs some refinements in assigning reasonable ratings to the middle of the rankings or dealing with skipped tests (0 scores).
EDIT: There is a bit of additional discussion on the topic in this post on Para's blog and its comments: http://puzzleparasite.blogspot.com/2012/04/tvc-xii-recap.html
Edited by MellowMelon 2012-04-04 10:22 AM
Full XLS spreadsheet: http://mellowmelon.files.wordpress.com/2012/04/lmi-tvc-alt-rankings...
Not too many rank changes here, and the top 3 stayed the same. My main reasoning for considering this was that the system used here seemed a bit sensitive to the top score. People who had their bad day on TVC X or TVC XII seemed to get a lucky break, while people with their best relative performance on those tests didn't have it count as much - reminiscent of motris's complaint about his Samurai solve in the Marathon being his best relative performance yet still getting thrown out as his worst time. Whether the end rankings with this formula make more sense than the old I'm not entirely sure of, but perhaps other people can offer their own views.
Actually, this whole issue of things being sensitive to the top score is something I've felt is a bit of a weakness of the current LMI ratings in general. The stated reason is to give the top scorer appropriate compensation for their performance, but it seems weird to implement this by knocking everyone else's prorated score down. The exponential distribution the CTC introduced, based around the top 10% score instead of the top score only, seems to solve this problem and possibly do a better job of compensating the top scorer, since there is a steep rate of change in the exponential distribution near the top. I admit I haven't thought about all of the relevant issues in their entirety though. Also, if you check the full XLS file you'll realize the formula probably needs some refinements in assigning reasonable ratings to the middle of the rankings or dealing with skipped tests (0 scores).
EDIT: There is a bit of additional discussion on the topic in this post on Para's blog and its comments: http://puzzleparasite.blogspot.com/2012/04/tvc-xii-recap.html
Edited by MellowMelon 2012-04-04 10:22 AM
@ 2012-04-04 8:11 PM (#7095 - in reply to #7092) (#7095) TopPosts: 199

Country : United States
motris posted @ 2012-04-04 8:11 PM
You can certainly pivot rankings around whatever solvers you want ordered better, but you lose resolution in different areas. Here, if you applied something like this to the LMI rankings to try to get the 20th place solver at the right value (with 200 solvers on average), you would greatly affect the top standings because some tests would now be worth more than others. I think the top must always be fixed. The question is where a second pivot point be placed, and should there be another besides just the median result as currently in the LMI rankings. I'll note that applying this fix on Marathon, for example, makes Samurai worth much much more than some other puzzles. Which is an opposite problem from it being worth 0 for me, but this is the problem with a pick N from M system as you need equivalent pieces to drop out one or two.
I'll note, as I did on Para's blog, that the easiest way to rank solvers is to simply let them all finish a test. And then directly compare the times (or, equivalently, to use proportional time bonus so a person solving at 20 points per minute rate actually gets 20 points per minute rate bonus to keep the lead they earned). When solvers have not completed the test, and point values are somewhat arbitrary, you are going to have some misorderings that are unavoidable. With TVC, I note one problem is that early "big wins" got suppressed by smaller time bonus. TVC XII had more time bonus, but also so many more puzzle points for a solver to win. If TVC IX had an equivalent 19 puzzles, the eventual result could have been as big. Typos/errors are a whole different problem to talk about. And if you've watched my LMI tests, you know what I think is needed there.
I'll note, as I did on Para's blog, that the easiest way to rank solvers is to simply let them all finish a test. And then directly compare the times (or, equivalently, to use proportional time bonus so a person solving at 20 points per minute rate actually gets 20 points per minute rate bonus to keep the lead they earned). When solvers have not completed the test, and point values are somewhat arbitrary, you are going to have some misorderings that are unavoidable. With TVC, I note one problem is that early "big wins" got suppressed by smaller time bonus. TVC XII had more time bonus, but also so many more puzzle points for a solver to win. If TVC IX had an equivalent 19 puzzles, the eventual result could have been as big. Typos/errors are a whole different problem to talk about. And if you've watched my LMI tests, you know what I think is needed there.
@ 2012-04-05 4:04 AM (#7097 - in reply to #7095) (#7097) TopCountry : United States
MellowMelon posted @ 2012-04-05 4:04 AM
motris - 2012-04-04 8:11 AM
You can certainly pivot rankings around whatever solvers you want ordered better, but you lose resolution in different areas. Here, if you applied something like this to the LMI rankings to try to get the 20th place solver at the right value (with 200 solvers on average), you would greatly affect the top standings because some tests would now be worth more than others. I think the top must always be fixed.
You can certainly pivot rankings around whatever solvers you want ordered better, but you lose resolution in different areas. Here, if you applied something like this to the LMI rankings to try to get the 20th place solver at the right value (with 200 solvers on average), you would greatly affect the top standings because some tests would now be worth more than others. I think the top must always be fixed.
Honestly, affecting the top standings is one reason I am proposing this; I'm not a big fan of how the current system handles things on either side. I also don't think there is an objectively perfect system, and your second paragraph agrees. My argument is that pinning to the top 10% does a better, even if imperfect, job of valuing individual tests then pinning to the top finish only, for both of podium finishers and those in the top 20. I think my post and Para's have explained how it works for the top 20 region better already, so I won't repeat that here.
For why I think it works better for the top finishers, the basic reason is that a person with a particularly strong performance is compensated for it by knocking everyone else's score down. But other competitors who get closer 1st place finishes on other tests are awarded the exact same 1000. An indirect method of compensation like this doesn't seem to work as well, especially when you have features like discarding worst performances. On the other hand, a top 10% system more directly rewards a strong performance by giving a very high NS. The only way a rival can equal that NS is to similarly blow everyone else away on another test; if they can't do that, they don't deserve to have such a high value factor into their rating. You might call this valuing tests differently; whatever it is, I consider it an advantage of the system.
In short, I think the pinning at the top should be done at the point that best predicts how a typical top finisher might be expected to do. I've felt even before the TVCs that the 1st place score does a much better job of telling how good of a day someone had than actually doing this. Top 10% isn't a perfect predictor either, but it should be closer to the mark.
(sorry to get a bit off topic from the TVC; wouldn't mind if an admin split this thread)
@ 2012-04-05 5:12 AM (#7098 - in reply to #7097) (#7098) TopPosts: 199
Country : United States
motris posted @ 2012-04-05 5:12 AM
And I'll have to agree to disagree. I'd rather have an imperfect system with a fixed ceiling than a different imperfect system with a variable ceiling and much greater risk to overweight a given test, particularly when I see the largest problem coming from the range of scoring systems and bonus sizes on the monthly tests which make them a lot more like apples, oranges, and umbrellas than just a pile of apples. Some give partial time bonus for n-1/n correct. Others do not. Some give proportional time bonus. Others do not. Some have 50 finishers, others have one or none. And then there are outliers like my Decathlon test (huge points for last puzzle) or Tom's Nikoli Selection (huge points for puzzles you aren't intended to finish) which are built for huge point differences exclusively for the top 5 or so but for no one else and certainly not the 10th percentile who don't get to the big puzzles. Curve around the Nikoli Selection and I bet it counts as 1.7 tests for H.Jo and 1.5 for me, compared to say the Screen Test. So am I wrong to think you would give H. Jo 1700 in your system? Why should Tom's test be valued more than others, when it is just because of the particular scoring and timing that it became an issue? Imagine those individual marathons were each worth say 50 more points on the Nikoli Selection. The point value was arbitrary. Now H. Jo might earn 2000 points. His relative performance is not changed at all. So if we cannot get objective measures for relative performance uniform across tests, I do not want any system that blows up those performances without fixed bound. I'll accept a "less valuable" 1000 as a result of normalization when a test is an oddball over an artificially valuable 2000 any day. I wouldn't mind curving 800 to the 80th percentile too or something like that. The median is probably too low for the other pivot point, given all 0 tests are dropped anyway.
If I was designing a yearly scoring system from scratch, I would never consider test "points" at all. I would make a system that projected finish times based on puzzle solves/time throughout the test and then use exactly the real and projected finish times for everyone's solving. Some good implementation of instant grading could collect enough time-dependent data to make this modeling fair, and to separate those who are done from those who have entered something wrong, to get a true measure of position in the test. It would be like monitoring runners around a race. I don't need to know beforehand where the hills and valleys are so long as I see some finishers and have a handful of splits. Data makes better scoring easy. We knew a lot more about all the puzzles after seeing the Marathon results than before. Just the number of solvers of each puzzle might be enough data to project things right.
Edited by motris 2012-04-05 5:44 AM
If I was designing a yearly scoring system from scratch, I would never consider test "points" at all. I would make a system that projected finish times based on puzzle solves/time throughout the test and then use exactly the real and projected finish times for everyone's solving. Some good implementation of instant grading could collect enough time-dependent data to make this modeling fair, and to separate those who are done from those who have entered something wrong, to get a true measure of position in the test. It would be like monitoring runners around a race. I don't need to know beforehand where the hills and valleys are so long as I see some finishers and have a handful of splits. Data makes better scoring easy. We knew a lot more about all the puzzles after seeing the Marathon results than before. Just the number of solvers of each puzzle might be enough data to project things right.
Edited by motris 2012-04-05 5:44 AM
@ 2012-04-06 12:14 AM (#7104 - in reply to #7007) (#7104) TopPosts: 315
Country : The Netherlands
Para posted @ 2012-04-06 12:14 AM
I think the main point I wanted to address was to make sure that performances in different tests can be accurately compared as you employ a best 3 out of 4 score system. In the LMI scoring system every test is counted, so when someone has a runaway performance, the difference between other players is still counted towards the standings and still compares the difference between all players.
I had to get a normalised score of minimally 770 in TVC XII to beat Hideaki in the overall standings as I had to gain 77 points on him and my lowest normalised score was 693 before that. But it would mean I had to have beaten Hideaki by 230 normalised points in the last test. So if I had beaten him by a whopping 225, I wouldn't have gotten 3rd place, even though I clearly beat him in 2 out of 3 tests, which happened to be the test with the lowest normalised scores. This is the problem I think currently exists and should be dealt with. The best 3 out of 4 system is what causes problems in the current TVC scoring system and should somehow be adjusted in my opinion.
The easiest would just be to abolish the best 3 out of 4 system and use all 4 tests for the final standings. Although I assume this was implemented because using all 4 tests had caused problems before.
I had to get a normalised score of minimally 770 in TVC XII to beat Hideaki in the overall standings as I had to gain 77 points on him and my lowest normalised score was 693 before that. But it would mean I had to have beaten Hideaki by 230 normalised points in the last test. So if I had beaten him by a whopping 225, I wouldn't have gotten 3rd place, even though I clearly beat him in 2 out of 3 tests, which happened to be the test with the lowest normalised scores. This is the problem I think currently exists and should be dealt with. The best 3 out of 4 system is what causes problems in the current TVC scoring system and should somehow be adjusted in my opinion.
The easiest would just be to abolish the best 3 out of 4 system and use all 4 tests for the final standings. Although I assume this was implemented because using all 4 tests had caused problems before.